Trust, not blockchain, is the new currency: Invest early in data privacy

Contributors:
Alisa Bergman
Nishant Bhajaria
Technical Privacy Expert, Author of “Data Privacy: a runbook for engineers”
Data is a key business asset in the digital economy. Companies with access to large datasets are increasingly valued higher than those associated with physical products or more traditional assets (e.g., data technology companies are valued substantially higher than airlines that own planes and exclusive lucrative licenses to certain routes).
Long before the pandemic, Gartner predicted that in 2022 companies would be valued on their information portfolios. Therefore, companies have a strategic imperative to understand what data they have, how it can be used/re-used, and what compliance investments are needed to realize its benefits while maintaining trust. This is best achieved by a privacy-by-design approach leveraging technology-enabled data governance leading to great customer experiences that drive business value and minimize exposure.
Companies that have underinvested in their privacy programs are at risk of legal and regulatory fines and requirements to purge both the data they collect as well as any “tainted data” (e.g., algorithms developed using the data illegally collected, used or shared).
These risks are not academic and the penalties are high: global data protection regulators routinely act on consumer and employee complaints associated with poor data hygiene and practices. Since enforcement of the EU General Data Protection Regulation began in 2018, regulators have issued more than 900 fines totaling 1,544,575,254 euros.
Moreover, when looking at a company's brand and trust story, data privacy is increasingly factoring into the calculus. Employees want to work at companies who are doing right by their consumers who are also making choices based on privacy, while data governance and privacy protections are becoming a focus of the investment community in companies’ environmental, social and governance strategies.
A key issue in data governance or management is the need to respect a purpose limitation. That is, in some circumstances, data collected for one purpose may not be used for another purpose without obtaining additional user consent. This is the case even where data is in the public domain or seemingly freely available. For example, Spain's data protection authority issued a $1.1 million fine to a company that allegedly scraped individuals' publicly available data and used it in credit reports. While the data was made publicly available for one purpose, the company did not get buy-in or consent from the users to collect and use their data for an unexpected, secondary purpose.
Another example of this is a company that could collect data for a security purpose — such as requiring a cellphone number for multifactor authentication, but does not have proper user notice, consent or broader governance/controls in place to provide internal stakeholders with clarity on whether that same data could be used to provide a service-related notice about an expiring credit card or perhaps a wholly different purpose like telemarketing activities related to a new product.
Data collected to provide a service but subsequently used for product improvements or artificial intelligence/machine learning is also instructive. Under many legal frameworks, if you obtain data when providing a service as a data processor, there are rules about how and whether a company can use that data for its own marketing or other purposes. In such scenarios, you can find useful guidance from France’s data protection authority, the Commission nationale de l'informatique et des libertés. There are similar questions under the California Consumer Privacy Act about whether companies can maintain a “service provider” designation when it comes to data reuse.
These issues and concepts are not totally new. Even in the U.S., laws like the 1996 Health Insurance Portability and Accountability Act have concepts of primary and secondary uses of health data. There are nuances: certain data can be used for treatment, payment and operations without additional consents, but as you would expect, the use of that same data for marketing would need more. Similarly, in other contexts, data collected for fraud detection by security teams may not be automatically used for personalization upon identity verification.
To address and manage these complexities, it’s critical to understand data lineage. Simply put, data lineage is “a map of the data journey, which includes its origin, each stop along the way, and an explanation on how and why the data has moved over time.” The lineage will help guide what, if any, additional notices and permissions may be needed. The best way to address, or limit, potential data misuse is to embed controls in the data at an early stage, a concept we will discuss later in this article.
When developing a privacy by design foundation for data use, companies should account for at least these three key parameters of restrictions on data use (in addition to business objectives):
- What legal requirements or commitments govern the use of the data you have collected? For example, an email address is not particularly sensitive if it maps to a business contact or a test account, but if collected from a child or pharmacy, bank or even from someone in Europe, the use of it may trigger additional rights, obligations and permissions.
- What was agreed to in relevant data use and sharing agreements? Did it come from a partner, was it collected on a certain platform with permissions or restrictions that need to be respected? As a company’s first-party data becomes even more valuable, it will get harder to firm up agreements on data rights and restrictions. Companies will need to find ways to code and operationalize these requirements.
- Do your company policies restrict the use of data to align with your unique brand, to differentiate on privacy and as part of your trust story or as a result of regulatory commitments?
Having data appropriately tagged and managed accordingly is critical to help ensure the data that needs to be ringfenced or otherwise put off-limits in certain geographic regions or contexts is respected to enable the data to be used properly in other scenarios.
What makes it hard to implement and enforce meaningful controls to make these decisions?
The emergence of a more democratized and bottom-up engineering culture means that managers and central IT have less ability to help enforce guardrails on data handling. The widespread embrace of mobile computing, broadband internet and global IDs means data exchange and sharing at very low latencies is an accelerant. All of these collectively mean that making sound judgments around data usage has to occur amid a backdrop of big data and bigger ambiguity.
Another major challenge is the lack of a consistent approach to data protection requirements. There are regional differences to privacy, with countries, states and provinces interpreting the same laws or privacy principles differently. This makes the task of operationalizing privacy even more daunting.
To make matters even more interesting, there is the matter of balancing data minimization and data quality.
You could be rightfully skeptical of vast data stores for machine learning models but also recognize that for truly unbiased models you need sizable datasets; less data could mean entrenched bias as well as re-identification risks remain.
This is where privacy can become an enabler and differentiator, rather than a blocker. The complexity around data can affect companies in several ways, ranging from enforcing user safety, fairness, and information accuracy. Privacy is different in that it offers an operational template; engineers and attorneys can build scalable controls in the data and infrastructure. They can do so using a central privacy team and/or decentralizing some of their capabilities by having engineering teams own them. The upshot is that solving for privacy requires you to look at your platform holistically, rather than as a collection of disconnected product silos.
In other words, privacy engineering can potentially help solve a range of socio-technological problems.
A good starting point for solutions can be found through refactoring and reuse of current approaches, processes and infrastructure that work well in your environment. Privacy engineering, as described by one of the authors of this piece in their recent book “Data Privacy: A runbook for engineers,” offers a template for such scalable refactoring.
As an example, you could leverage the “shift left” philosophy employed by security teams as they invest in anomaly detection and asset monitoring to cover data classification, lineage and normalization. Think of data ingestion in a company as a horizontal funnel, with the narrow end on the left-hand side representing the point when data first enters the company’s tech ecosystem.
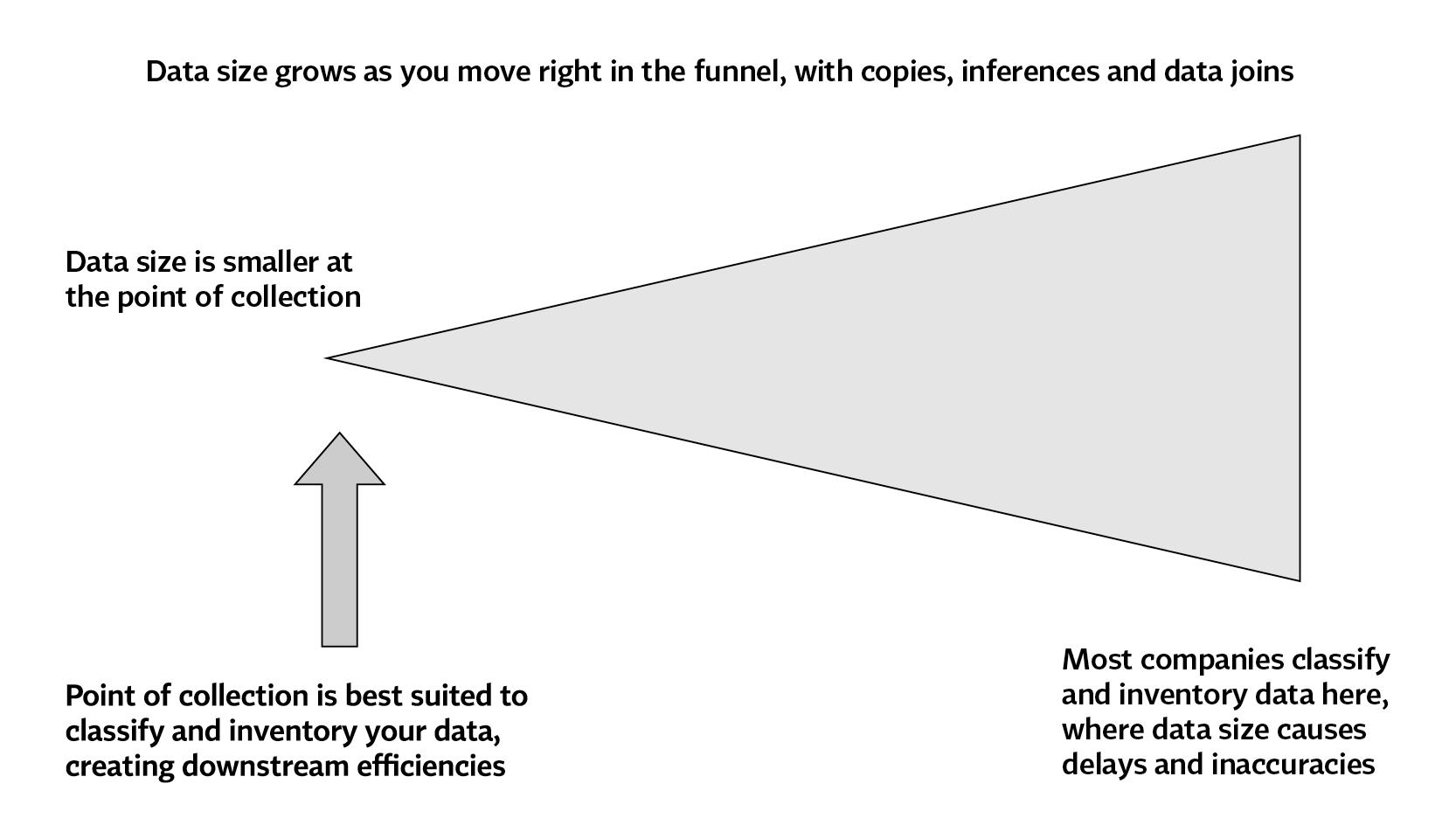
Companies should classify, label and start documenting the lineage of incoming data at or shortly after the point of ingestion and the classification criteria could be based on the three parameters described above and, in the diagram. Given that data only gets more sizable — and therefore more difficult — to manage as you move to the right in the funnel, it will be easier to identify the data components and requirements. This becomes especially critical given the volume and nature of data — think unstructured data with an IP address buried seven levels deep. Imagine trying to enforce anonymization or deletion policies at the right-hand side. Instead, performing data inventory on the left-hand side — by applying tags to the data identifying its privacy risk, retention periods, usage restrictions, access controls, etc. — will make enforcement easier throughout the data lineage process.
For example, an email address could be detected using programmatic tools that would detect data along the lines of “@” followed by text followed by “.” and finally followed by common domains like “com” or “edu” or “org.”
This technique could help privacy engineers at a company (fictitiously named “GrowMore”) detect both of the following email addresses:
● username@gmail.com
● username@growmore.com
The use of classification and labeling in our “shift left” approach allows early inferences that can be leveraged as the data moves to the right in the funnel; we can be reasonably confident, in this example, that the first email belongs to a customer while the second belongs to an employee. As such, during inventory process, the emails could be tagged as follows:

In the above table, the customer email is tagged as “personal data” and “P0,” which indicates a high degree of privacy sensitivity. It is also mapped to technical privacy controls to encrypt and delete it, as well as any optouts that need to be surfaced to the customer.
By contrast, the second email is marked as “business data” and “P2” since it possibly belongs to an employee who may be testing the company’s platform. As such, enclosing the technical privacy controls in square brackets means that those policies are optional.
Implementing data inventory in this fashion over time — first manually, then via automation — will help build machine learning models that will provide both scale and accuracy.
Having built privacy engineering controls into the data, you could similarly map your products and features to user consents, as the diagram below shows.
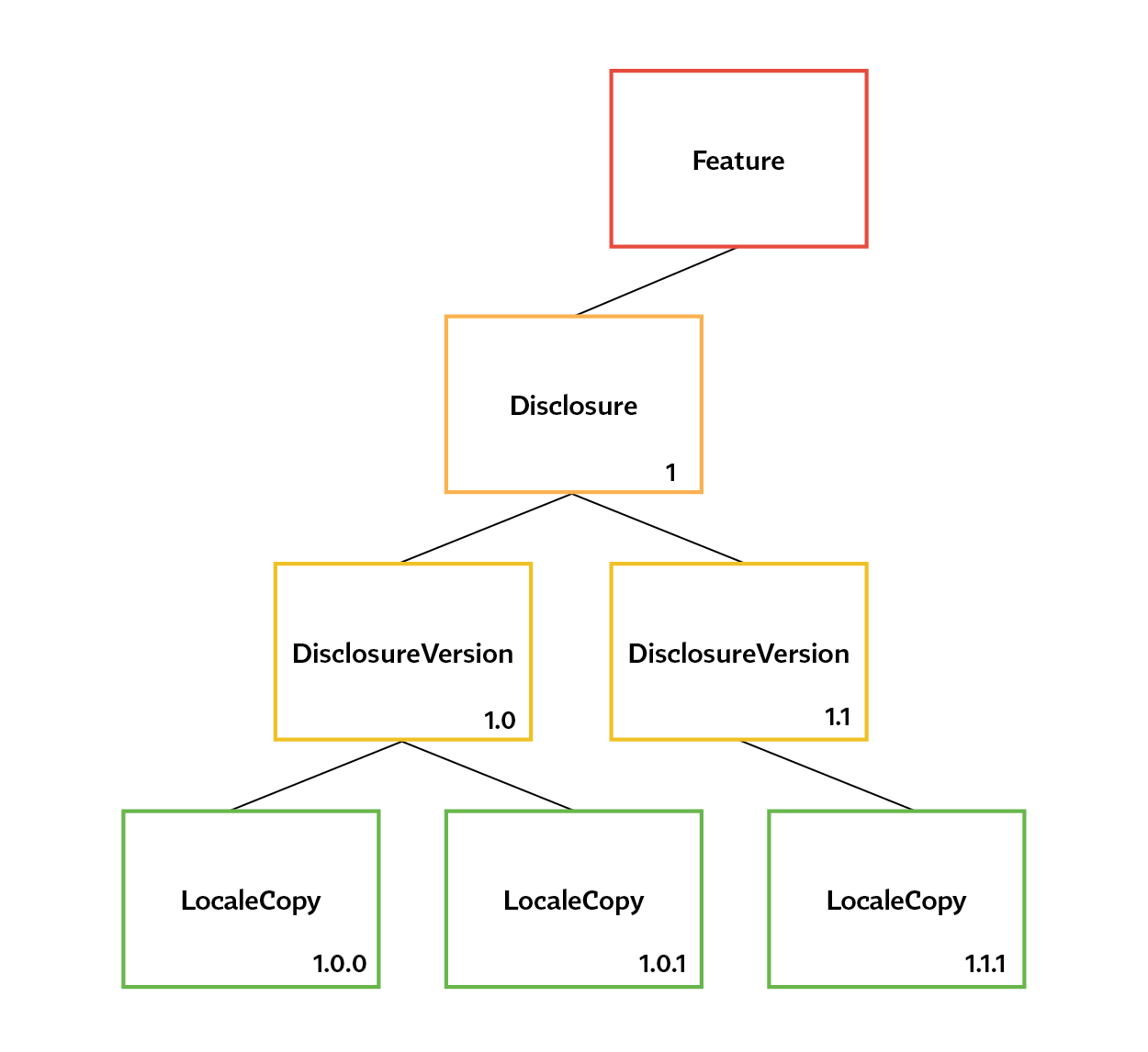
Per the diagram, an individual feature could be mapped to disclosure(s) based on the data it uses. This should ideally occur right after the data inventory process we just looked at. Each disclosure could then have multiple versions, each of which could be translated for different jurisdictions (country, region, etc.) from where your customers access the platform. As an example, a company could initially start with a catch-all privacy policy for the U.S.; as laws and business needs evolve, the legal team could update the policy, thereby creating an archive of versions; the company could then carve out copies for different states. Collectively, you would end up with a tree-like structure with various disclosures, versions, and translations akin to what we see in the diagram.
This is an example of how you could “shift left” in the funnel (i.e., start early). Early classification and categorization of data helps map the correct privacy policy early in the development cycle. This strategy then enables technical enforcement by operationalizing privacy tooling that maps to the appropriate privacy policy. This approach connects organizational risk (by way of data) to legal controls (privacy policy) to data protection (privacy tooling) early in the process.
When done at scale, you will end up not just with better privacy controls, but more mature data management for your company and higher user trust.
You could go a step further and have privacy engineers consult with other engineers and product managers and modify design decisions before they become embedded into code and architectures. This will help confirm the aforementioned data inventory and accelerate the privacy impact assessment process. Privacy engineers can also help prevent superfluous data collection and map data usage to verifiable consent collection backend logic.
The benefits of this approach could range from a more purpose-driven and manageable data footprint, reduced data-storage costs, lower impact of any data leaks and improved data quality that in turn will provide richer insights.
Privacy and data protection are achievable and can be a force multiplier providing verifiable compliance and business benefits. So, “shift left” and invest early in trust for impressive rates of return.
Photo by Taylor Vick on Unsplash

This content is eligible for Continuing Professional Education credits. Please self-submit according to CPE policy guidelines.
Submit for CPEs


