Using sensitive data to prevent AI discrimination: Does the EU GDPR need a new exception?

Contributors:
Marvin van Bekkum
PhD candidate
iHub
Frederik Zuiderveen Borgesius
Researcher at the Institute for Information Law
University of Amsterdam
Organizations can use artificial intelligence to make decisions about people for a variety of reasons, such as selecting the best candidates from many job applications. However, AI systems can have discriminatory effects when used for decision making. For example, an AI system could reject applications of people with a certain ethnicity, even though the organization did not plan such discrimination.
In Europe, an organization can run into a problem when assessing whether its AI system accidentally discriminates based on ethnicity, as the organization may not know the applicant’s ethnicity. In principle, the EU General Data Protection Regulation bans the use of certain “special categories of data” (sometimes called sensitive data), which include data on ethnicity, religion and sexual preference.
The proposal for an AI Act of the European Commission includes a provision enabling organizations to use special categories of data for auditing their AI systems. In our paper, "Using sensitive data to prevent discrimination by artificial intelligence: Does the GDPR need a new exception," we explore the following questions:
- Do the GDPR’s rules on special categories of personal data hinder the prevention of AI-driven discrimination?
- What are the arguments for and against creating an exception to the GDPR’s ban on using special categories of personal data to prevent discrimination by AI systems?
Though this only discusses European law, it is also relevant outside Europe, as policymakers worldwide grapple with the tension between privacy and nondiscrimination policy.
Do the GDPR’s rules on special categories of personal data hinder the prevention of AI-driven discrimination?
We argue that the GDPR prohibits such use of special category data in many circumstances. Article 9(1) of the GDPR contains an in-principle ban on the use of certain special categories of data. These categories of data largely overlap with protected characteristics from the EU's nondiscrimination directives, as shown in the figure below. Organizations would, in principle, need to collect people's protected characteristics to fight discrimination in their AI systems.
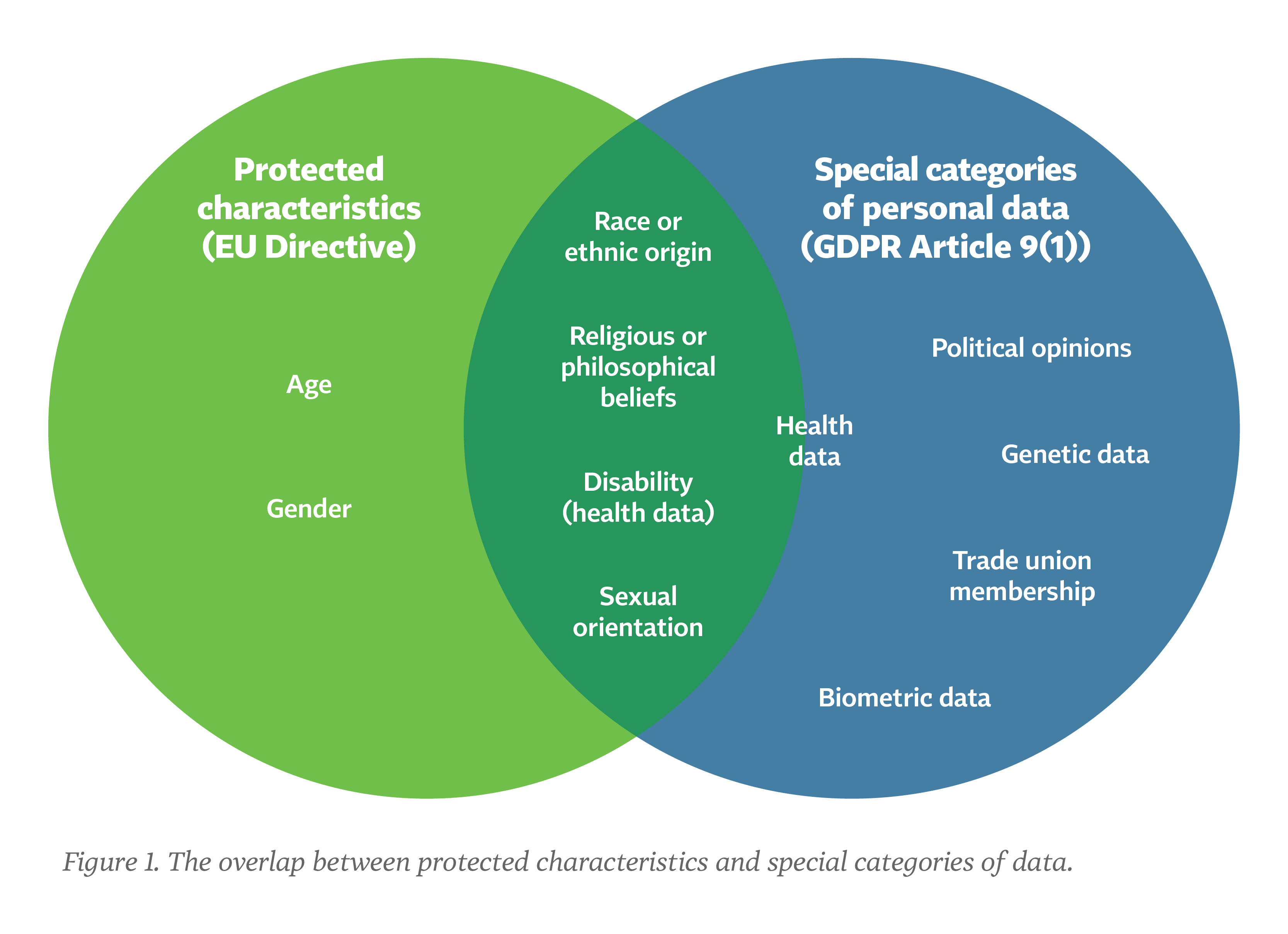
There are exceptions to the ban of Article 9 of the GDPR, but such exceptions are generally not suitable to enable AI auditing. In certain situations, an organization might be able to obtain valid consent from data subjects for such use. However, in many cases, obtaining valid consent would be close to impossible.
Suppose an organization asks job applicants whether they consent to the use of their ethnicity data to reduce bias in AI systems. Job seekers, however, might feel they have to consent. Under the GDPR, such consent would usually be invalid, because only “freely given” consent is valid. In other situations, an EU or other national law would be needed to enable the use of special categories of data for AI debiasing. At the moment, such laws are not in force in the EU.
What are the arguments for and against creating an exception to the GDPR’s ban on using special categories of personal data to enable preventing discrimination by AI systems?
During the year of working on this paper, we mapped out arguments for and against a new exception. Sometimes we said such an exception would be a good idea. But after sleeping on it, one of us would called the other to say: "Actually, the risks are too high — such an exception should not be adopted." Our opinion kept shifting throughout the writing process. In the following paragraphs, we briefly summarize the arguments we found. See our paper for in-depth clarification.
In favor of an exception, our arguments are:
- Organizations could use the special category data to test AI against discrimination.
- AI discrimination testing could increase the trust consumers have in an AI system.
The main arguments against an exception are:
- Storing special categories of data about people interferes with privacy. People might feel uneasy if organizations collect and store information about their ethnicity, religion or sexual preferences.
- Storing data always brings risks, especially sensitive data. Such data can be used for unexpected or harmful purposes, and data breaches can occur. Organizations could abuse an exception to collect special categories of data for other uses than AI discrimination testing. For instance, some firms might be tempted to collect loads of special categories of data, and claim they're merely collecting the data to audit AI systems.
- In addition, allowing organizations to collect special category data does not guarantee the organizations have the means to debias their AI systems in practice. Techniques for auditing and debiasing AI systems still seem to be in their infancy.
Finally, our paper discusses possible safeguards to help securely process special categories of personal data if an exception were created. For instance, one option could be a regulatory sandbox where data protection authorities supervise the correct storage and use of the data.
We really enjoyed researching and writing this paper. And we have learnt a lot by presenting drafts of the paper at workshops and conferences for people in various disciplines, such as the Privacy Law Scholars Conference and events by the Digital Legal Lab in the Netherlands.
Our paper shows the many different interests at stake when creating an exception. In the end, how the balance between different interests is struck should be a political decision. Ideally, such a decision is made after a thorough debate. We hope to inform that debate.
This blog post summarizes the main findings from a paper that the authors published in Computer Law and Security Review (open access).

This content is eligible for Continuing Professional Education credits. Please self-submit according to CPE policy guidelines.
Submit for CPEsContributors:
Marvin van Bekkum
PhD candidate
iHub
Frederik Zuiderveen Borgesius
Researcher at the Institute for Information Law
University of Amsterdam
Tags:



