Are there risks of using public clinical trial data under GDPR?

Contributors:
Khaled El Emam
Professor, School of Epidemiology and Public Health
University of Ottawa
Mike Hintze
CIPP/C, CIPP/E, CIPP/G, CIPP/US, CIPM, CIPT, FIP
Member Partner
Hintze Law
A number of regulatory agencies around the world have established, or are piloting, policies and regulations for the public sharing of clinical trial documents. The European Medicines Agency has already started sharing clinical trial documents under its Policy 0070. Health Canada has published amendments to the Food and Drug Regulations allowing for more public sharing of clinical trial documents. The U.S. Food and Drug Administration has recently initiated a pilot program to evaluate the sharing of clinical trial documents.
Given that clinical trial documents contain personally identifying health information about trial participants, it is necessary to anonymize these documents. The EMA and Health Canada have published guidelines (draft in the case of the latter) for the sponsors to anonymize the documents and then give them to the agency to publish them. The FDA anonymizes the documents themselves in consultation with sponsors, and then publishes them. These documents, once published, would be used by a multitude of different users and organizations for secondary analysis. These users can be, for example, academics, other (possibly competing) sponsors, the media, and citizen scientists.
While there are efforts among the agencies to harmonize their anonymization guidance and practices, they are governed by different privacy laws and, especially in the case of the FDA, are implementing quite a different anonymization methodology. This raises the question of what the risks would be to the users of these public clinical trial documents if the anonymization performed for a public data release was not adequate and the public documents still have a high risk of re-identification?
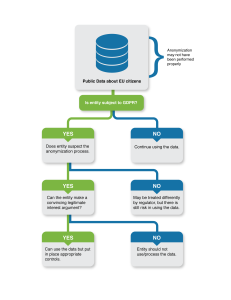
Risk and obligations
The decision tree allows us to analyze the risks to and obligations of public clinical trial data users. Specifically, depending on a series of conditions, it indicates the risks and obligations of data users under the GDPR.
Is the entity subject to GDPR?
The first question is whether the data user (or entity) is subject to the GDPR at all. The GDPR applies to entities that process personal data. There are a handful of exceptions. For example, it does not apply to a “natural person in the course of a purely personal or household activity," but the relevant limitation here is the territorial scope of the GDPR, which is set out in Article 3. It states:
- This Regulation applies to the processing of personal data in the context of the activities of an establishment of a controller or a processor in the Union, regardless of whether the processing takes place in the Union or not.
- This Regulation applies to the processing of personal data of data subjects who are in the Union by a controller or processor not established in the Union, where the processing activities are related to: the offering of goods or services, irrespective of whether a payment of the data subject is required, to such data subjects in the Union; or the monitoring of their behaviour as far as their behaviour takes place within the Union.
Therefore, if it is an entity that has no establishment in the EU (e.g. no facilities or staff), does not offer goods or services to data subjects in the EU, and does not monitor the behavior of data subjects in the EU, it will not be subject to the GDPR. So even if an entity receives and processes data relating to EU persons, it will be beyond the territorial scope of GDPR enforcement. Few entities of any significant size would meet all of these criteria, but for smaller entities, or certain entities that are inherently focused on a non-EU local market, it may be relevant.
If the entity analyzing the document is not subject to the GDPR, then it can use and analyze the data without consideration of whether that data was properly anonymized or not; the anonymity of the data, at least from the perspective of the GDPR, is no longer relevant.
Does the entity suspect the anonymization process?
If the entity is subject to the GDPR, then the next question is whether the entity suspects or knows whether the anonymization was performed well or not. There is no exception in the GDPR based on knowledge of the nature of the data. If the data is personal data, then it does not matter whether the recipient of the data knows or believes it is personal data or anonymous data. But this may be one place where there is some divergence between the technical answer and the practical answer. If the data appears on its face to be anonymous, and the recipient is using it based on a good faith belief that it is anonymous, a regulator is going to be less likely to bring an enforcement action against that recipient. If, on the other hand, the regulator concludes that the recipient knew of or should have known that the data was personal data, it will be less likely to exercise restraint in enforcement.
If the method of anonymization utilizes a published and generally accepted methodology, and there is empirical support for it, then the entity can have more trust that the data is adequately anonymized. More concern is warranted if the methodology and its justifications are not published, and there is a lack of supportive empirical evidence that the risk of re-identification is indeed very small.
If the entity is confident that the document was anonymized adequately, then they can use the information in it without additional obligations. If not, then the final (and probably the most important) set of considerations relate to how the data is being used/processed.
Can the entity claim legitimate interest?
Assuming the document is personal data does not mean that recipients of the data cannot use or possess it. They must just use it in compliance with the GDPR. That means, for example, that the recipient must be transparent about the use, ensuring that this type of use is at least covered by their privacy notice. They must also employ “appropriate” security for the data, but if the data is already publicly available, that bar is going to be fairly low.
It also means that they must have a legal basis for processing that data. They obviously will not have the consent of the data subject. But if the data is being used for research purposes that are arguably in the public interest, and their use creates little or no risk to the individual data subjects (beyond the risk that already exists due to the public release of the data), they may have a strong “legitimate interests” basis for processing the data. On the other hand, if they are using it mostly for commercial reasons, and especially if there is any attempt to link the data back to identified data subjects, then the legal basis may be more challenging. Using data for these types of commercial purposes is where the greater risk is likely to come into play.
Appropriate controls
Given that the data has already been made public, the “appropriate” controls that would be the most meaningful would be those designed to prevent misuse of the data. Misuse could be thought of as processing for a purpose beyond that for which the entity has a solid “legitimate interests” argument. Misuse could also be thought of as any attempt to take advantage of the weak anonymization to seek to re-identify individual data subjects. So an entity that chooses to receive and process this data should adopt policies against re-identification or use of the data beyond the identified research purpose and put in place organizational (and perhaps technical) measures to enforce and assess compliance with such policies.
An entity using this data, even if it is public data, should assess the adequacy of the anonymization performed by the sponsor or the agency and be cognizant of their obligations under the GDPR.
photo credit: Coffee-Channel.com library_books_knowledge_information_bookshelves_bookshelf_data_college - Must Link to https://coffee-channel.com via photopin (license)

This content is eligible for Continuing Professional Education credits. Please self-submit according to CPE policy guidelines.
Submit for CPEsContributors:
Khaled El Emam
Professor, School of Epidemiology and Public Health
University of Ottawa
Mike Hintze
CIPP/C, CIPP/E, CIPP/G, CIPP/US, CIPM, CIPT, FIP
Member Partner
Hintze Law



